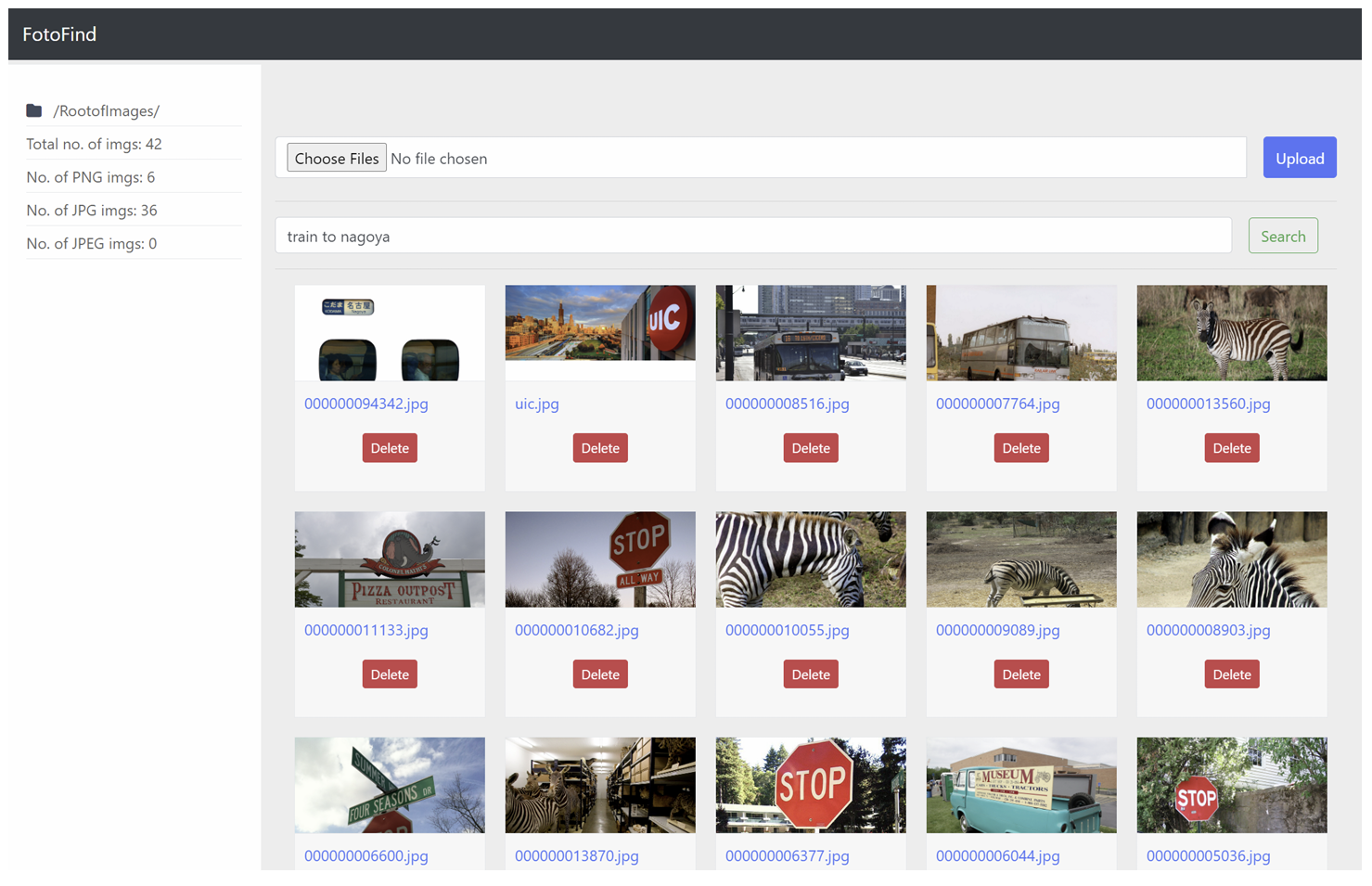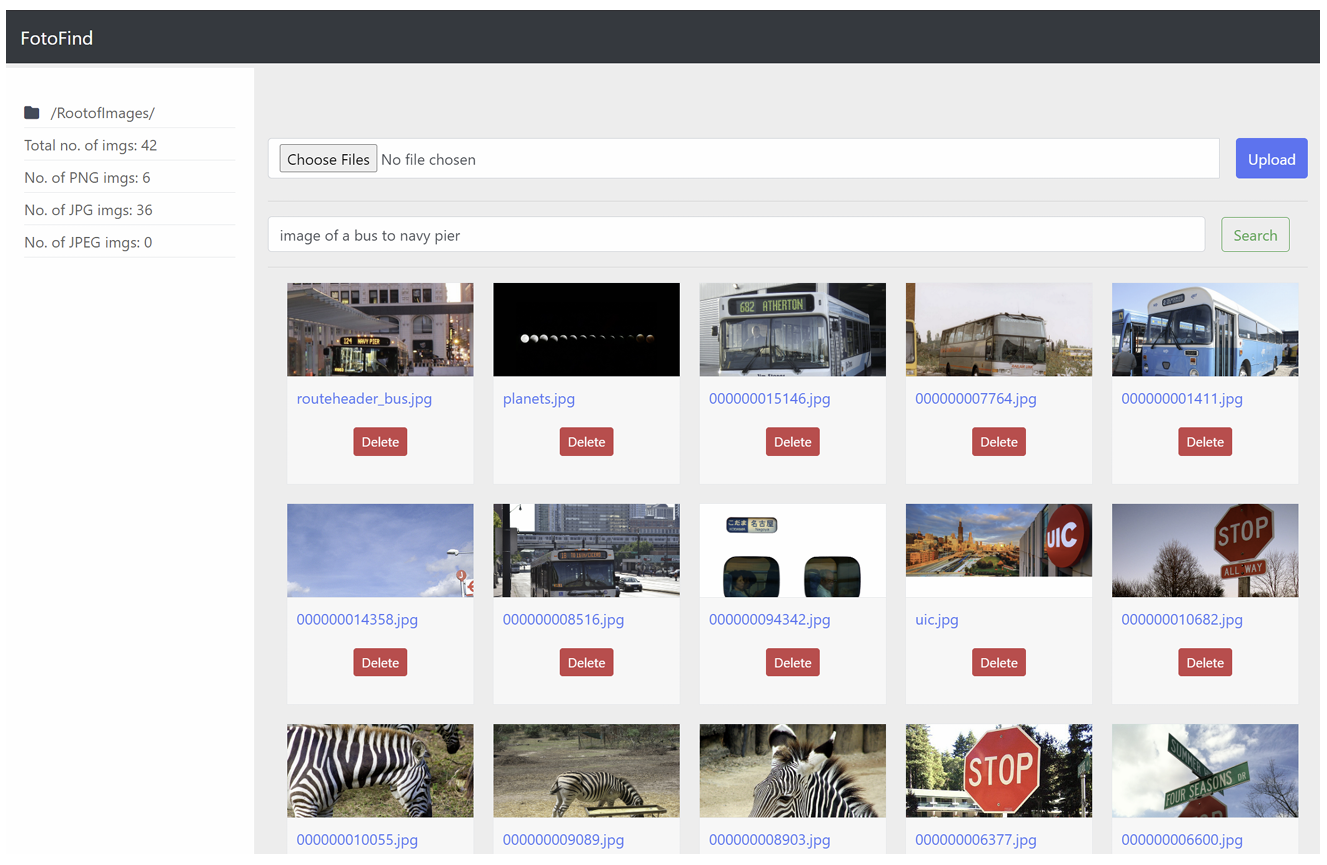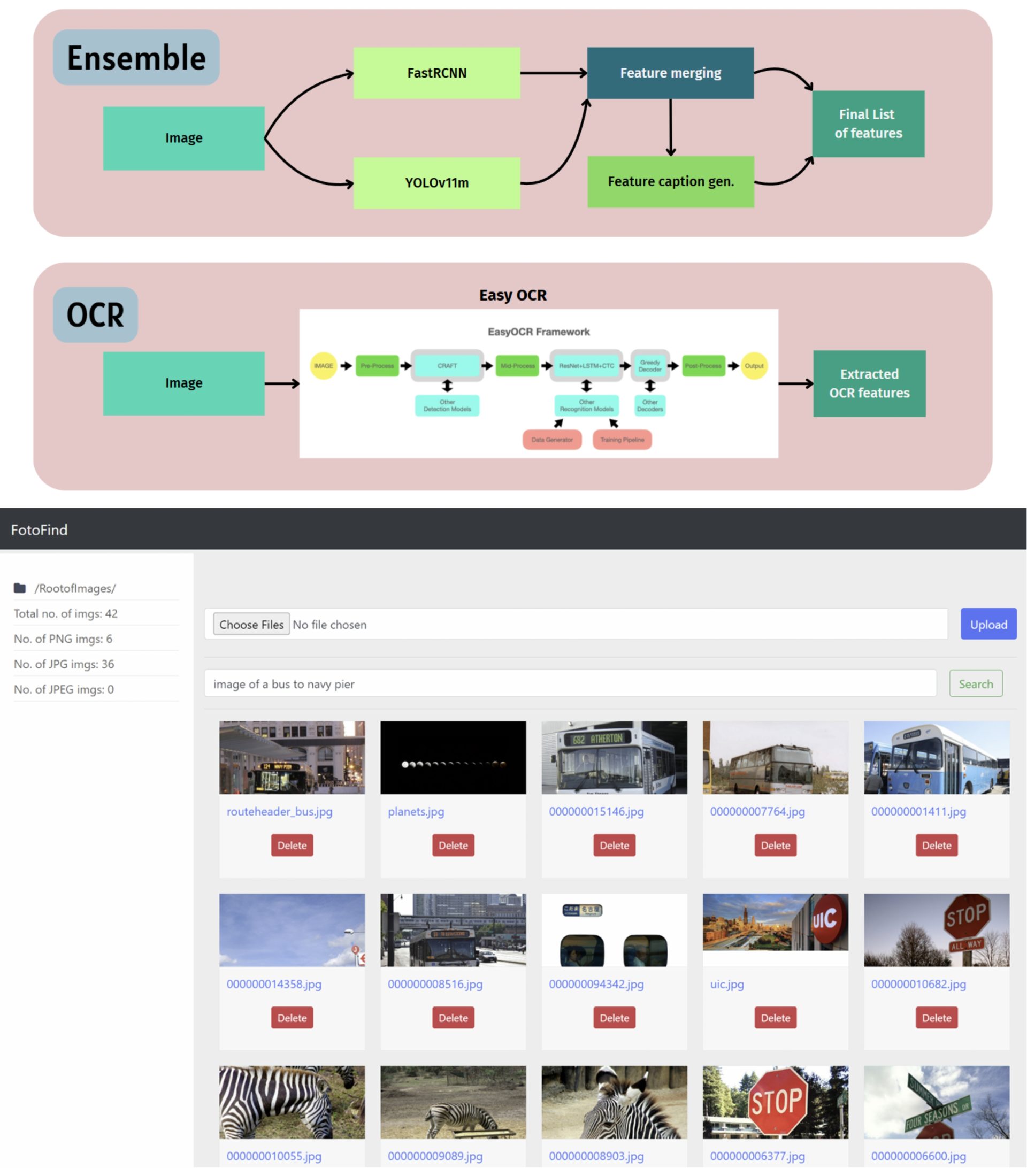
FotoFind: Galley Search Engine
The dramatic rise in digital image creation has presented modern systems with massive repositories of visual data. Managing, indexing, and retrieving relevant images is crucial now due to the various forms in which photos are stored, from personal photo libraries to organizational databases, scientific imagery surveillance data, etc. Conventional solutions often rely on user-generated tags or rudimentary filenames, providing only limited search capabilities. Such manual metadata tagging can be inconsistent and quickly becomes infeasible for extensive datasets. To address these bottlenecks, FotoFind implements a pipeline of advanced computer vision and natural language processing models to glean semantic information from images automatically. The synergy of object detection, captioning, and OCR ensures that each image, regardless of its content, gains enriched metadata that can be leveraged to facilitate more nuanced text-based searching. The aim is to streamline and automate a process that would otherwise depend heavily on manual labor.
Technologies Used:
Deep Learning Frameworks: PyTorch, Transformers (ViT-GPT2), EasyOCR
Web Framework: Flask
Search and NLP: TF-IDF, Cosine Similarity
Database: MySQL
Front-End: HTML, CSS, Jinja2 Templates
Storage: Garage – S3 object storage (selfhosted for DEV env), AWS S3 (for PROD)
Development Tools: Python 3.9+, PyTorch Lightning, MySQL Connector, OpenCV